
谷歌论文提前揭示o1模型原理:AI大模型竞争或转向硬件
 摘要:
...
摘要:
... OpenAI最强模型o1的护城河已经没有了?
仅在OpenAI发布最新推理模型o1几日之后,海外社交平台 Reddit 上有网友发帖称谷歌Deepmind在 8 月发表的一篇论文内容与o1模型原理几乎一致,OpenAI的护城河不复存在。
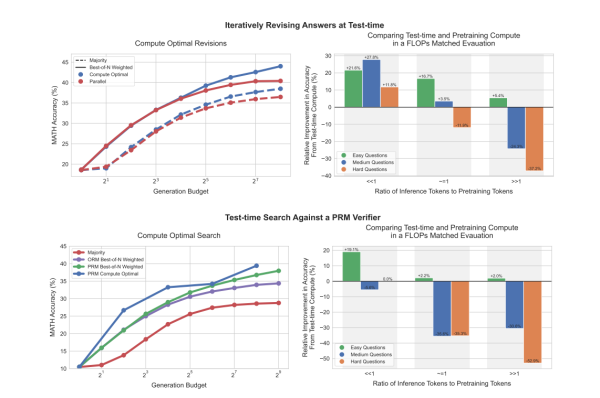
澎湃科技(www.thepaper.cn)注意到,谷歌DeepMind团队于今年8月6日发布上述论文,题为《优化 LLM 测试时计算比扩大模型参数规模更高效》(Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters)。

谷歌DeepMind团队于今年8月6日发布的论文
在这篇论文中,研究团队探讨了大模型(LLM)在面对复杂问题时,是否可以通过增加测试时的计算量来提高决策质量。这项研究表明,增加测试时(test-time compute)计算比扩展模型参数更有效。基于论文提出的计算最优(compute-optimal)测试时计算扩展策略,规模较小的基础模型在一些任务上可以超越一个14倍大的模型。
无独有偶,另一篇由谷歌和斯坦福大学研究人员于今年1月发表的论文《思维链赋能 Transformer 解决本质上的串行问题》(Chain of Thought Empowers Transformers to Solve Inherently Serial Problems)也提出了类似的观点。该论文探讨了“思维链”(Chain of Thought,简称 CoT)技术,旨在突破 Transformer 模型在串行推理方面的限制。
传统的Transformer模型擅长并行计算,但在处理需要逻辑推理的复杂问题时表现欠佳。CoT的核心思想是让模型模拟人类的思考方式,通过生成一系列中间推理步骤,来解决复杂问题。
OpenAI 近期发布的o1 模型,或正是上述理念的实践。o1模型在给出答案之前,会生成一系列中间推理步骤,不断完善自己的思维过程,尝试不同的策略,并能识别自身错误。随着更多的强化学习和思考时间,o1的性能持续提升。
有网友表示,“所有的秘密突破和算法最终都会随着顶尖开发者在行业内的流动而传播到其他公司和开源社区。”谷歌也表示没有人拥有护城河,这也促使OpenAI将o1-mini的速度提高7倍,每天都能使用50条;o1-preview则提高每周50条。
有网友评论道:“唯一可能形成护城河的是硬件,至少在可预见的未来是这样。”也有人认为,如果AI大模型公司无法解决对显存的依赖,英伟达可能会直接掌控谁能够获得计算能力。而如果微软或谷歌开发出在自研芯片上运行速度快10倍的模型,情况也会变化。
目前,英伟达在AI大模型算力的分配上占据主导地位。值得注意的是,OpenAI近期也被曝出其首款芯片计划,采用台积电最先进的A16级工艺,专为Sora视频应用打造。这些迹象表明,大模型的竞争已不仅局限于模型本身,硬件能力也成为关键因素。在AI领域,谁能拥有更强大的算力,谁就可能在下一阶段的竞争中占据优势。







